
One Hour is Too Long (Or Is It?)
A while ago, a software engineer I know asked for my opinion on his startup’s CI. Their End-to-End (E2E) suite took about an hour to run, and the team was agonizing over whether to move it from every PR (presubmit) to a nightly job because it felt “too slow.”
An hour? One, single, hour? For an E2E test suite? My answer: Don’t touch it. In a startup, there are a million things with higher ROI than shaving minutes off an hour-long E2E suite, especially if your unit test coverage isn’t optimal yet. And certainly do not switch to running it nightly. Getting coverage that late will grind your development cycle to a halt, discovering bugs which may have been introduced by any PR in the past 24 hours(!!!).
When I posted about this on Twitter the pushback exposed an interesting aspect of software engineering culture: Many engineers felt that an hour-long CI was torture. They were waiting for the green checkmark before moving to the next task. Some even waited for the code to hit production before starting something new.
To me, this pointed at a deeper problem: it wasn’t actually about the time the CI took. It was about trust. The CI was failing late, the tests were flaky, and the developer workflow was strictly synchronous.
Since then, using AI agents to write code and execute tests asynchronously have become a widespread practice in software engineering, so perhaps engineers have gotten used to working asynchronously – but not necessarily in a good way.
The 20-Second Rule
Here is my controversial take: Unless your CI pipeline takes less than 20 seconds, you have already context-switched.
If you sit and watch a progress bar for two minutes (or let your agent run…), your mind drifts. You check email, you scroll social media. The “cost” of the context switch is already paid. By then, the impact on productivity is the same if your CI takes 5 minutes or 60 minutes.
The key to productivity isn’t making the CI faster (though faster CI is definitely nice to have); it’s moving to an asynchronous mindset.
Once you submit your change for review, move on. (I hope) you’re already waiting for a human to review it (an inherently slow process). Treat your CI like a code reviewer: it might ping you later with “comments” (i.e. test failures). Address them later, when it’s convenient for you.
To make this async workflow feasible, we need to increase the reliability of the CI so it doesn’t waste developer time debugging random flakes (which may or may not be related to our code changes) and failures that could have been caught earlier.
The Testing Pyramid
You may be familiar with the testing pyramid. At the bottom, you have a wide base of Unit Tests; in the middle, a smaller layer of Integration Tests; and at the top, a tiny peak of End-to-End (E2E) tests.
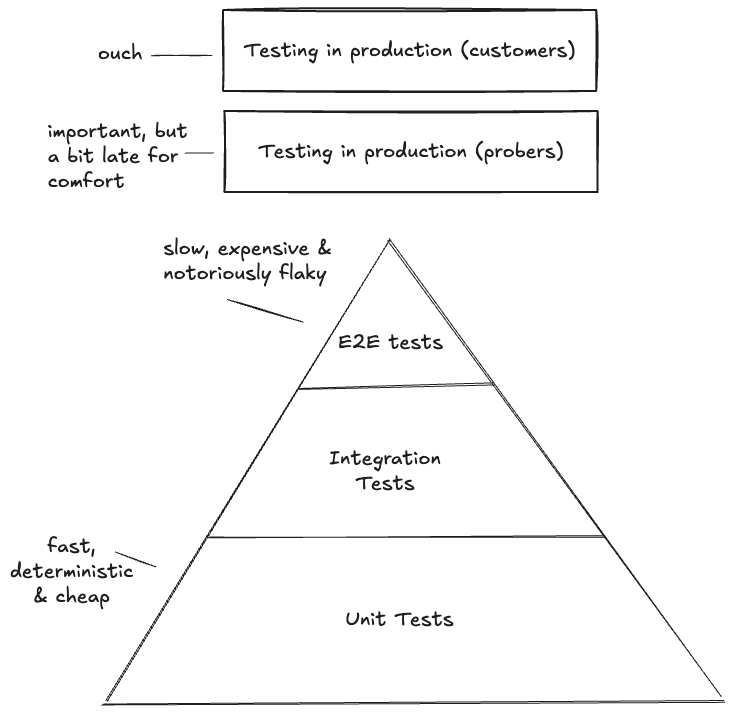
I’ve also added the layers of testing in production with probers (you control the scenario) and customers which are always testing you in production (you don’t control the scenario) for completeness.
Many organizations go straight to the full coverage E2E tests and don’t invest in unit tests in order to “move faster”. And in an utopian fantasy world that may work – but reality is governed by a trade-off between Speed, Cost, and Coverage:
Unit Tests: Are cheap and lightning-fast, but they take time to write. And when they are isolated to the point of absurdity, their coverage of actual system behavior drops to near zero.
E2E Tests: Offer the highest coverage and confidence, but they are incredibly expensive. This isn’t just about cloud bills; it’s also the SWE cost of debugging flaky tests and the architectural cost of finding defects too late in the software development life cycle.
Shift Left
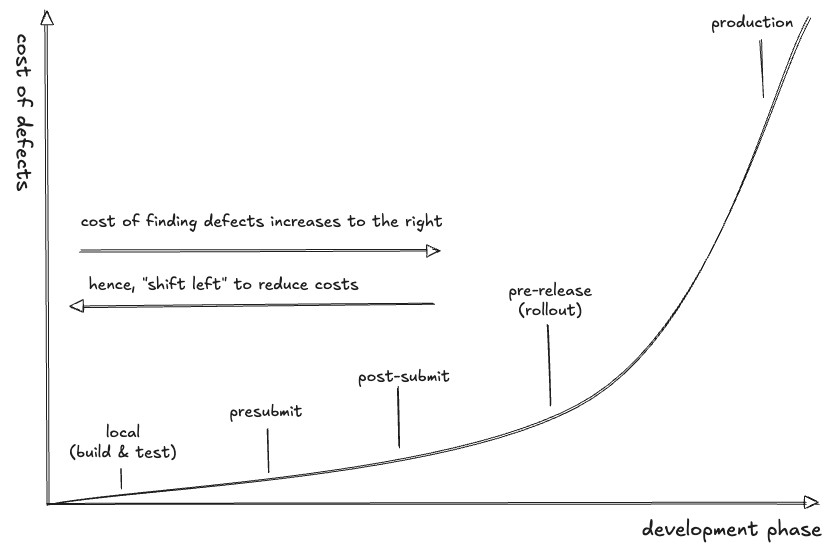
So, how do we increase CI reliability (and decrease costs)? By getting better signals earlier (to the left). And the best way to do that is to stop writing unit tests.
I say “stop writing unit tests” for the shock value, but I’m also serious. Traditional unit tests focus on isolation, and the industry standard practice is:
- A unit test should test one small “unit.”
- Dependencies should be mocked to ensure we are only testing that unit of code in isolation.
The result? We mock our dependencies to infinity (and beyond) to ensure we only test a tiny sliver of logic. Our local write-build-test cycle passes quickly and perfectly but our tests:
- Are hard to maintain: Every developer needs to know the logic of every component, to make sure the mocks are written correctly. And over time that logic may change and will require ongoing updates to those mocks.
- Provide low confidence: Since we have mocked out all our dependencies, we don’t know how they actually behave. We also don’t know how our internal clients actually use our components, we just think our code is “correct”.
- Discover bugs only during integration tests: Since our mocks don’t represent the actual behavior and interaction between components, we discover integration bugs late in the software development cycle.
Our rigid interpretation of the unit layer – insisting that it must be isolated and mocked – gets us into trouble. We are optimizing for isolation at the expense of meaningful coverage.
Small Tests: Size vs. Scope
In the book Software Engineering at Google (chapter 11), Adam Bender writes:
“… there are two distinct dimensions for every test case: size and scope. Size refers to the resources that are required to run a test case: things like memory, processes, and time. Scope refers to the specific code paths we are verifying…”
If a test runs in a single process, stays in memory, and finishes in milliseconds, it is a small test. It doesn’t matter if it hits one class or twenty. By using real implementations (or high-fidelity fakes) instead of mocks in our small tests, we catch bugs at build time that usually wait for the “hour-long” integration stage and break the speed/cost/coverage tradeoff.
What is a fake and how does it differ from a mock?
A fake is a simplified but functional implementation of a dependency that actually works, such as an in-memory database or a lightweight service that mimics real behavior without the overhead of network calls or disk I/O. Normally, teams maintain fakes for components they own and the commit to the integrity of the fake by testing it using the same tests that cover the real implementation.
In contrast, a mock is an object pre-programmed with expectations in the context of a test. It doesn’t have real logic but instead returns specific hard-coded values when called and is primarily used to verify that certain methods were triggered during the test or that your code reacts correctly to behaviors you expect.
Creating a fake is often much easier than you think and can be done incrementally, and pays off very quickly. As I often say, writing a distributed fully consistent persistent database is hard, writing a fully consistent database in memory is easy: it’s a synchronized hash table.
You should only mock code you don’t own (3rd party dependencies) where it’s infeasible to use a real implementation (e.g. cloud resources) and there is no better alternative to use, but this is dangerous as your assumptions about its behavior may be wrong. There’s no reason to mock code you do own (use a real implementation or create a fake if that’s not feasible).
AI Warning: Coding agents love writing mocks because it’s a well known pattern and easy to write and rewrite tests that pass, whether they are correct or not. Don’t let them get away with it.
How to Choose Your Test Type
To put this into practice, I suggest moving away from “Unit vs. Integration” distinction and toward a size-based framework.
1. Foundation: Small Tests
- Purpose: Verify correctness of functions, classes, or modules in the largest scope possible while staying fast and deterministic.
- When to use: As much as possible, for all logic and interaction validation.
- Test Doubles: Use real implementations first. If infeasible, use high fidelity fakes. Only use mocks as a last resort.
- Execution: local development cycle and automated presubmit.
2. Compromise: Medium Tests
- Purpose: Verify interaction and API contracts between 2-3 components and cover configuration permutations that don’t fit in a small test.
- When to use: Validating multi-process logic, backwards/forwards compatibility etc.
- Test Doubles: High-fidelity fakes. Use mocks only if there is absolutely no other choice.
- Execution: Presubmit if fast/hermetic or post-submit “nightly” if slow/heavy.
3. Safety net: E2E Tests
- Purpose: Validate user-facing scenarios and integrations with real dependencies in a deployed environment.
- When to use: Reserved for tests that must use real infrastructure or cover the full stack.
- Execution: Post-submit “nightly”.
We aren’t in a school exercise or a book. We’re building products in real life. Formal definitions shouldn’t get in the way of finding bugs. If your “unit test” is perfectly isolated but provides low signal because the mock was wrong, the test failed its only job.
Many E2E tests could have been a large-scoped yet small-sized tests. Shifting left means less E2E tests (and the flakiness and late signal that inevitably accompany them) and earlier, higher quality, easier to debug, signal.
The Beyoncé Rule
At Google, there is a well known Beyoncé Rule: “If you liked it, then you should have put a test on it.”
But in the spirit of shifting left, I’m proposing Beyoncé Rule 2.0: When a bug makes it all the way to a heavy integration test or, worse, to production, it’s because:
“to the left, to the left, everything you test should be shifted to the left”
If a bug is found in a slow E2E test;
Don’t you ever for a second get to thinking it’s irreplaceable.
You could have another test in a minute;
Matter of fact, it’ll run in less than a minute.
(OK, maybe that last verse is taking it a bit far)
Inspired by the “Testing on the Toilet” series and “Software Engineering at Google” book.