

I was away from my computer when I got a call from a junior developer I know. She was having trouble uploading a web application to Azure, and asked if I could help. I’ve never worked with Azure, but I assumed Visual Studio had a button which said something like “publish to Azure”. However, she couldn’t make heads or tails from the Azure tutorial, and while I was trying to understand where the difficulty was (other than the fact she wasn’t using Visual Studio, so the button I assumed was there was totally irrelevant), she said: “I understand the back-end has to go on the server, but where do the front-end files go?”
“Do you know how a web server works?”, I asked. “I guess not”, she answered.
If this seems stupid to you, this post is not for you. I give you permission to go read something else. This post is for me, setting up my first self hosted site about 10 years ago.
I had been working in web development for a few years, I guess, but we had DevOps (before it was called that) so the deployment process was a mystery to me. Hosting companies’ tutorials are notoriously impossible to understand, and I was in a similar situation. I had no idea what I was doing.
From my experience, many developers, even some of those who actively write web applications, do not understand how web applications work at the most basic level. Most tutorials one finds on the internet assume this knowledge already exists when explaining how to use their specific web development framework, which makes them very hard to follow for an absolute beginner. In this post I hope to bridge some of that gap.
There is no “internet”
Any sufficiently advanced technology is indistinguishable from magic.
Arthur C. Clarke
Some of you many have heard that “there is no cloud, it’s just somebody else’s computer”, well that’s true of the internet in general. The internet is just a whole bunch of computers connected together.
In very simple terms, each computer connected to the internet has an address called an IP (Internet Protocol) address. By communication protocol magic and some central service providers, requests can get sent to other computers using their IP address and responses get sent back to you to your IP address.

Your IP address looks something like 168.31.1.1. Now, that’s not so easy to remember. If you’re building a site about, let’s say, how to build websites, and you want people to be able to remember how to get there — you’ll probably want an address that’s easy to remember instead of a string of numbers. That’s the pretty name you see in the address bar of your web browser, for instance: www.absolutebeginnersguidetowebapplications.com, though I might recommend something shorter.
Now that you’ve bought and registered a pretty domain name and mapped it to your IP address, there are special servers called DNS (Domain Name Service) servers who know how to route traffic from that pretty domain name to your IP address. As there are many such servers around the globe, it may take some time for your domain name to propagate to all the internet, but usually the process is complete within 24 hours or so.
Further reading: IP address, DNS, Julia Evans on Twitter, A Non-Scary Introduction to Computer Networking.
How may I help you?

Once we have our domain name set up, we need to enable other computers to request things like web pages, emails, and other files from our computer. If you set up your computer to respond to such requests — congratulations! You have a server. To make your computer function as a server, you install a server application that knows how to do the magic of routing requests coming in from clients in a way that they will get the correct response.
Since I’m focusing on web applications, I’ll discuss HTTP servers — the type that serve web pages, though these principals apply to other types of servers as well.
A client is an application on a computer which sends a request to a web server. The most obvious type of client is a web browser, but other applications often use HTTP calls to get information from a server in the background. Such a request is sent using a url which includes information on what we want and where we want to get it from.
Example:
http://www.my-site.com/page?id=123456&cat=789
This url breaks down into the following parts:
http://is the protocol we’re using. HTTP for web requests.www.my-site.comis the address of the server. Remember our fancy domain name mapped to an IP address? This is it./pageis the resource I want to access on that server, AKA route.?id=123456&cat=789everything after the ? is called parameters. These are key=value pairs separated by &, which allow us to send additional information that can be used by the server.
Further reading: Web servers, HTTP, URL.
Servers are like birthday cakes

Once the request has reached the server, it’s routed to some kind of handler that knows how to… well… handle the request and return the right thing.
The default handler would be for a static resource. A static resource is a file which is sent as-is to the client that requested it without any further processing. There’s no personal or dynamic information, just a file stored on the server.
Using only static files is pretty limiting, as you show exactly the same content to everyone who enters your site. Imagine social media as a static content site where everyone sees the same thing and nothing ever changes? Watching paint dry would be more entertaining.
That’s why most of the content we see on the internet is built on-the-fly with code running in the server. This enables us to show different content depending on our own logic. It could be something as simple as greeting you with your registered name or hiding content behind a paywall, or as complicated as the entirely personalized experience on social media sites.
Let’s bring in the birthday cake metaphor:
- The first layer of the server is the physical server — a computer with a network connection). It receives requests.
- The next layer is the web server application — a piece of software that knows how to parse a request and route it to a handler.
- The last layer is a handler — software specific to the request that knows which content to create and return.
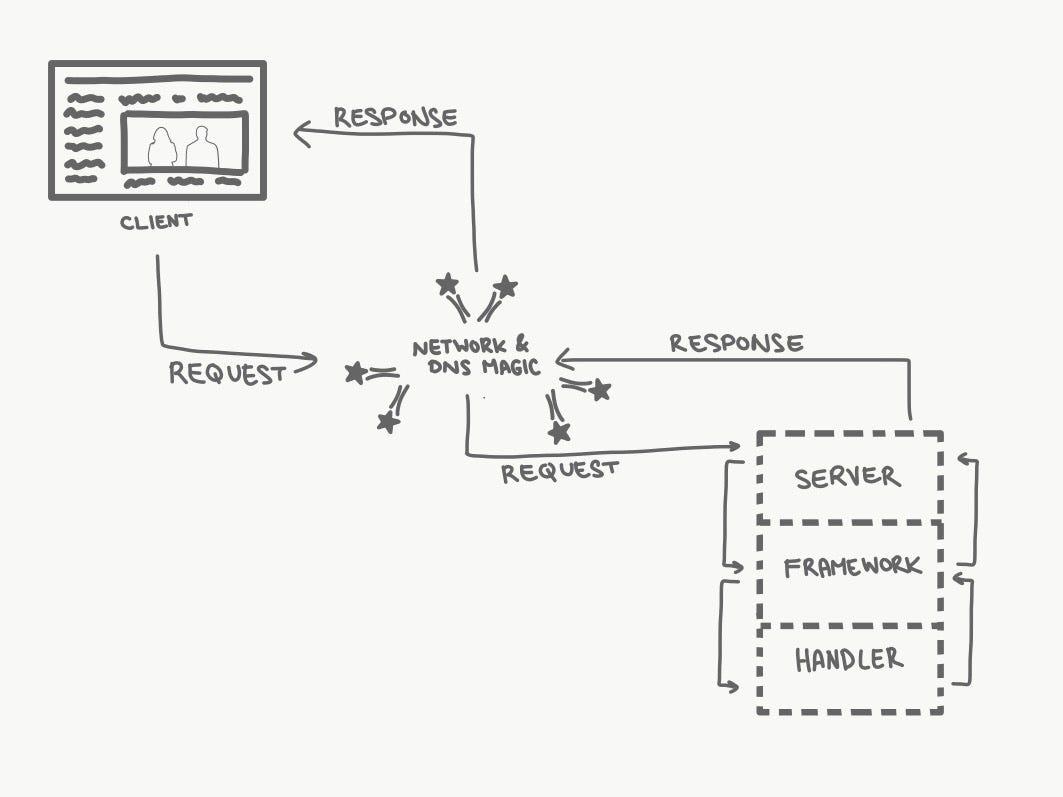
The last two layers are where most developers come in — they install a web server application, decide which framework they’re going to use, and implement the handlers for each route.
A handler is just a method that gets parameters and runs code that returns a response to the client in a form the client can use. Note that static files have an important part even in dynamic content. We’ll get more to that in the next section.
Further reading: ASP.NET, Spring, Node.js, Pylons and many more web frameworks for any programming language.
Let me get back to you on that

I mentioned before that handlers return responses that clients can use. But what responses can clients use? And how? In this section I’ll explain at a very abstract level what browsers can do and what we need to provide so they can do it.
HTML
This is the entry point to any web page. A browser knows how to parse and display HTML (Hypertext Markup Language). HTML represents the structure of a web page and tells the browser what to display — headers, content, tables etc. Many handlers return HTML content.
CSS
CSS (Cascading Style Sheet) tells the browser how to display the HTML content. That’s what makes web pages pretty (or ugly…). It determines which font to use and in what sizes, background colors, page layout etc.
JavaScript
The browser can also run JavaScript code to make the HTML change dynamically inside the browser (even without contacting the server for more information).
JavaScript can also be used to make background AJAX (Asynchronous JavaScript and XML) calls. This allows the client to make requests and receive responses from the server without navigating to another page. Most modern web pages do this a lot as it makes the user experience smoother.
JSON
It’s debatable if JSON (JavaScript Object Notation) should get its own header or not, as it’s “just” a way to serialize objects, but since it’s such an important part of web today — I think it deserves a place of honor.
JSON is a key-value text notation which represents a serialized object. Often, a handler will not return HTML, but objects which are then parsed by JavaScript inside the browser and processed into HTML which can dynamically be added to the page.
Static Resources
Both CSS and JavaScript can be written inline, directly embedded in the HTML content. However, since they tend to be long and complex and most websites reuse them across different pages, it’s useful to have them in separate files. These files are declared as elements in the HTML and the browser “knows” it must download them from the server.
Other static resources declared in HTML and downloaded automatically by the browser can be special fonts, images and other embedded media (e.g. videos or gifs).
All these files are stored somewhere on the server (or a different server…) and are retrieved using static resource handlers, usually without any custom code, just the default handler provided by your web server.
HTML, CSS, JavaScript are all considered “Front-End” because even though they come from the server — they are parsed and executed by the client. Everything that happens on the server — the code executed in the handlers, access to databases etc. is considered “Back-End”.
Further reading: HTML, CSS, Javascript, AJAX, JSON.
I hope this gave you a high level overview of how web applications work. I do recommend you explore some of the links I added for further reading, but this post should be enough to give you a starting point for understanding tutorials for specific web frameworks, which can be very confusing if you have no idea how how client files get to the client.
Now go build your own web app. You’ve totally got this!